无
企业地址:北京市朝阳区酒仙桥北路甲10号电子城IT产业园106号楼荣联科技大厦
联系电话:010-62602000
企业邮箱:marketing@ronglian.com
成立时间:2001 年
企业规模:
注册资金:66,158.0万
浏览次数:1872
 获赞0
获赞0企业地址:北京市朝阳区酒仙桥北路甲10号电子城IT产业园106号楼荣联科技大厦
联系电话:010-62602000
企业邮箱:marketing@ronglian.com
成立时间:2001 年
企业规模:
注册资金:66,158.0万
浏览次数:1872
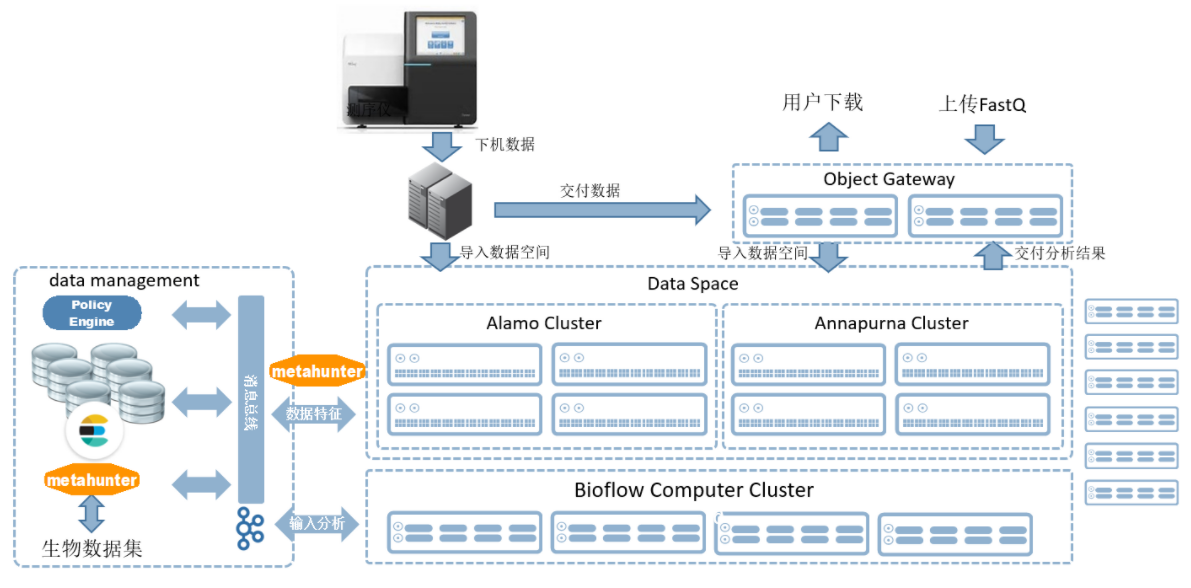
测序仪下机数据经过分数据机之后,会存储到BIOSTACK Data Space数据空间中。在数据存储的过程中(一边写,一边修改),会通过左侧的黄色图标的Metahunter动态的将元数据,提交到消息总线上去了,消息总线会把这些信息传递给后端数据特征库集群,数据特征库集群实际上是由数据库(关系型或数据仓库),甚至是搜索引擎,如Elastic Search,组成的。在计算分析的过程中,通过数据特征生成的数据集,会作为一个有效的输入,注入到计算集群中去。计算集群在经过调度计算资源(CPU、memory),以及调度数据的位置之后完成一次分析,而分析完的结果也会再反向注入到数据特征库集群来丰富数据特征。
方案架构
主要功能
高速分数据机
可完成下机数据的格式转化;将转化后的数据分配到存储平台(Anna和Alamo);其中数据格式的转化效率极高,以 Hiseq X10 下机数据为例,分数据效率是普通bcl2fastq 的 5-6 倍!
BIOSTACK数据空间即存储平台
数据空间包含 Anna 存储和 Alamo-D,分别应对高 IOPS 和高带宽的需求。同时多集群能够实现统一部署、统一管理。
BIOSTACK数据管理平台
存储系统端内置的“Metahunter”模块,智能追踪数据和元数据的变化,在服务器端通过 MetaView 自动提取数据特征信息,使得用户无需关心数据的存储路径,通过数据特征就能实现快速数据发现、数据组合、多维度数据观察,极大的提升了用户数据管理的效率。
BIOSTACK分布式计算平台
Bioflow 计算调度系统,采用全分布式架构设计,能够多个调度协同工作,消除了传统集群调度器自身的瓶颈,同时联合同构、异构集群,实现跨多个计算集群、存储集群调度生物作业任务,保证无论是后端集 群规模还是调度器本身都不会限制整体生物信息分析计算系统的扩展能力; docker 封装应用程序,免除应用部署难题;通过 bioflow 封装流程,免除用户 编写流程的烦恼。
可视化流程分析和报告输出
BIOSTACK生物数据分析云平台支持自主发布分析工具,用户不需要再命令行下编写脚本,通过可视化界面填写参数,就可以生成自己专属的工具,并在流程编辑中,通过鼠标拖拽的方式,将工具串成流程,全力支持企业定制化自有流程。
方案优势
一体化设计,工厂预集成,“插电即用
BioStack采用工厂预集成方式,在出厂前完成软硬件系统的测试和调优,所以整体性能更加优异,也更加稳定可靠。
BioStack真正做到了端到端产品级的解决方案,无需复杂的系统部署和软件调试,真正做到开箱插电即用。
嵌入优化的分析流程、数据集和参数
BioStack包括了行业主流的基因组分析软件、生物信息流程,确保输出的结果符合实验和数据分析的要求。
预先配置的专业数据集,帮助真正实现本地数据分析的快捷性、可靠性和操作标准化,减少复杂数据集导入的繁琐及相应人为错误的引入。
可视化流程组织和报告输出
BIOSTACK支持自主发布分析工具,用户不需要再命令行下编写脚本,通过可视化界面填写参数,就可以生成自己专属的工具,并在流程编辑中,通过鼠标拖拽的方式,将工具串成流程,全力支持企业定制化自有流程。
BioStack统一管理系统,应用操作简单直观
BioStack中集成了常用的生物信息分析软件、数据集和流程,用户无需自行安装配置软件以及数据集,大幅节省了用户配置软件的时间。分析软件的流程化和分析结果可视化,为基因组研究提供了一站式的解决方案。这在提高工作效率的同时,也降低了对分析和操作人员的门槛需求,摆脱了传统繁琐的命令行操作,真正实现了“傻瓜化”的操作方式。
所有软件、数据集和流程均可在Web界面下直接操作,其中流程部分可实现一键式的运行,为用户提供极大便利。
分布式计算与存储突破集群规模瓶颈
BioStack采用分布式存储系统来解决生物信息数据空间和数据持久化的问题,使得空间和性能可以根据业务需要,弹性扩展。
BioStack中Bioflow作为分布式计算、调度引擎可以让多个集群在一起,统一的调度,让用户看起来是一个集群一样。可以启动多个调度队列和调度实例,多调度器之间相互协作,突破单一调度器的性能瓶颈。




Q友评论Q友评论仅代表用户个人观点,不代表Q医疗立场